 tell
application "WebSTAR Search Indexer"
tell
application "WebSTAR Search Indexer"The WebSTAR Search Plug-In allows visitors to search the contents of the files on your site. WebSTAR Search indexes text files (including HTML) and PDF files, and provides an interface for very fast and powerful searching, including Boolean operators, relevance ranking, results formatting, and more. WebSTAR Search is based on Apple's Find By Content toolkit used in Sherlock (formerly known as "Apple Internet Access Toolkit", "AIAT" and "V-Twin").
WebSTAR does not install the WebSTAR Search Plug-In by default. Use the WebSTAR Server Suite Installer to custom install it. It does not require any additional RAM.
The WebSTAR Search Plug-In is always enabled, and will always be called by URLs ending in .search .
Before you can search, you must have an index : a file which stores data about the files to be searched in a special format. WebSTAR search uses this index, rather than opening each file and checking its data, for speed and flexibility. The example files include an example index, which indexes data in the Test Collections folder. You can create your own index of your own data--if you have very large data sets, you can even create multiple indexes.
for instructions, see Indexing and Index Files .
Once you have an index, you can access it by using a search form (an HTML form with an Action link to the index file) for the search. When a visitor types the search terms and clicks the "Submit" button, the browser sends a form action request to the WebSTAR server. Because the form URL suffix is .search , WebSTAR sends this request to the WebSTAR Search Plug-In, which searches the index for the requested terms, and returns the results in a formatted page.
for instructions, see Installation . For a search form example, see Search Examples
With WebSTAR Search, you can enter the words in your query in any order. The search engine will compare them to the data in the index: it will find all files with at least one of the search terms. When it returns the results, WebSTAR Search will automatically rank them from most relevant to least relevant.
WebSTAR Search performs a vector search , where every indexed document is stored in the index as a point in a multi-dimensional space (a vector ), and the dimensions correspond to terms found in the body of all documents. Normal queries are then interpreted as very short documents, and are also converted into a vector. The search engine then looks at the index for all document vectors within a certain distance of the query vector. Thus, the more that your query resembles the documents you are looking for, the better your results will be. That's why natural language queries, such as questions or descriptions, work so well with WebSTAR Search. For example, you could enter the query:
improve performance of web server
and get back results ranked according to how closely they resemble that query.
The search engine uses special functions to improve word matching: see Search Dictionaries .
In addition to the vector searching, you can add Boolean operators to your searches, if you prefer.
Another way to control the query is to explicitly group the terms --control the order of processing
For example, you may want to link the terms "Sherlock" and "Apple" and ignore "Holmes". So you can use the grouping brackets " [ " and " ] " to specify how the search should be grouped:
aiat | [[sherlock & apple] ! holmes]
WebSTAR search will automatically display formatted results of your search:
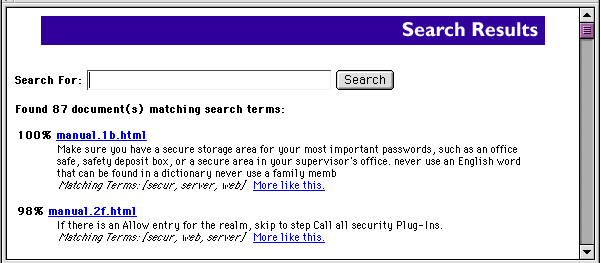
Note that the links for the results will take you to the beginning of the document containing the matched text. For an exact location, you must use the Find function of your browser.
See Search Dictionaries .
The default setting will find only the 10 most relevant documents which have a relevance ranking of 50% or greater.
In the example, you'll see that the form includes options for the searcher to specify the relevance, along with the total number of results. In this case, WebSTAR Search will, by default, display 10 results per page and provide navigation links to go forward and backward, if there are more than 10 matches.
You can use the Search Parameters in your forms and URLs to specify how many results, the relevance ranking, and how many to display per page. In addition, the section Search Tags Using WebSTAR SSI describes how you can use SSI commands to display the results listings within your documents.
The default search result page is stored in a STR resource of the WebSTAR Search file. You can use ResEdit or Resorcerer to open that file and copy the HTML file in that file, edit it, and paste the changes back into the resource.
Before and after working on this file, make backup copies. You can also re-install the file using the Installer. When you update WebSTAR Search, the changed resource will not be transferred, so you'll need to copy it to the new file by hand.
When you choose WebSTAR Search from the Custom Install options, following items are installed in the WebSTAR Plug-Ins folder:
WebSTAR Search automatically registers the " .search suffix". Make sure that all .search files are created by the WebSTAR Search Indexer application, and that they are always named with that suffix.
WebSTAR Search requires that the WebSTAR SSI Plug-In be installed.
The Search Examples folder in the Tools & Examples folder includes both simple and advanced example forms.
To try them out, follow these steps:
Then open a browser window enter your host name and the path:
/Tools%20%26%20Examples/Search%20Example/help.html
When you do a search, you'll see a result list that looks like this:
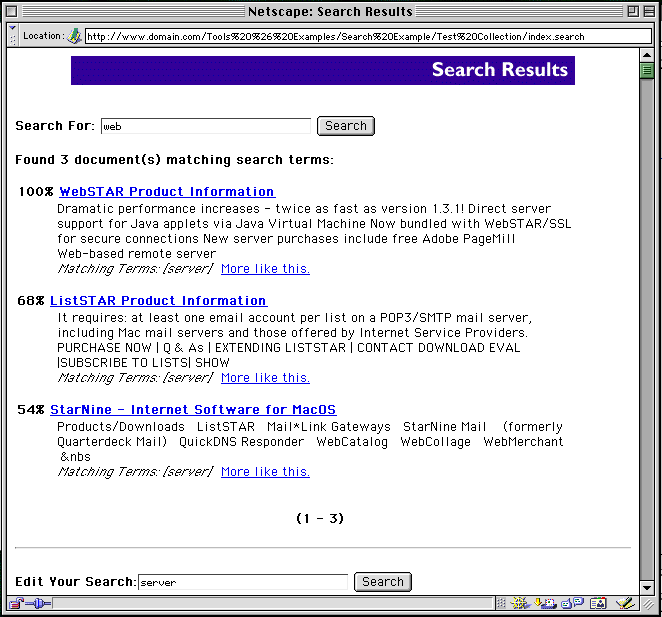
The Search Plug-In is very memory intensive. The exact amount of memory it requires depends upon the size of the index being searched, so large indexes may require more memory. To track memory use, check the Status panel memory fields (described in Memory ). Most of the required memory will be used during the first search performed, and will be retained by the Search Plug-In, rather than being released back to the WebSTAR server.
For instructions, see Server Application Issues .
The performance of the WebSTAR Search plug-in will benefit from both increased memory in WebSTAR and a larger system disk cache (set in the Memory control panel).
WebSTAR Search uses search index files , which contain words from the designated files in a special format. The Search Indexer application (located in the Plug-Ins folder) builds, updates, and tests the index files.

Every index file is associated with a search root folder in the WebSTAR folder hierarchy. The Search Indexer will analyze and store data for all the text and PDF files within that folder and its subfolders in the index file. Indexing PDF files is a resource intensive process. Depending on the size of the PDF file, you may have to allocate as much as 20 MB or more to the Indexer. In addition, you should not index encrypted PDF Documents --make sure that all your documents are publicly-accessible.
WebSTAR Search Indexer cannot follow aliases: the original files must be in the search root folder or a subfolder.
Once you create an index, you should update it regularly. You can use the Search Indexer application, or have WebSTAR update your searches automatically (see Search Plug-In Administration: Index Auto-Update ).
If you're supporting several Virtual Hosts, you can have multiple index files on for your server, each containing separate data, starting from different root folders. That way, visitors searching for data from one web site will not accidentally get results from a different, unrelated site.
Search Index Files cannot be moved: they must be generated on the disk and in the hierarchy in which they will be used.
Files created by WebSTAR, WebSTAR Admin, and WebSTAR Search (with Creator Codes of " WWW ω", " WWWx ", and " WSIx ") will not be indexed.
To avoid having a file indexed, move it out of the search root folder hierarchy, rearrange your folder hierarchy, or use an file resource editing application to change its Creator Code to " noIX ", which will indicate to the Search Indexer that this file should be skipped.
If you have security realms or confidential information in one of your indexes, name it carefully, and consider protecting it by using a security realm entry. That way, no one can search through it to find private data.
To create a search index, decide which folder will be the search root folder . The Indexer will open and index all text and PDF files in this folder and its subfolders. For security, you should not make your WebSTAR root folder the search root. You should also index your secure realms separately from the public data. Limit your indexes to data folders, and merge them later if you want cross-folder searching.
If you expect to use this application often, make an alias of it and put it in a convenient location.

See also Web File and Folder Name Rules .
Once you have created your index, you can design search forms and links for your visitors: see Web Tools For Searching .
You can also use the Search Indexer application to merge index files together. You can use this to index only some subfolders of a site and search them as one:
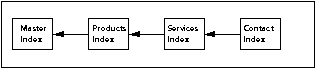
Note that each index can only have one other index merged into it. Therefore, you must design an index chain of parent and child indexes, as shown above.
To keep your indexes synchronized with your files, you must update them periodically. Updating is much faster than indexing, because it just checks the root folder and subfolders, and adds new files, removes deleted file data, and re-indexes the data in files that have changed. Updating can run in the background without slowing down your server.
You can update a single index or a master index by using the Search Plug-In Administration: Index Auto-Update .
Otherwise, you'll have to update the indexes using the WebSTAR Search Indexer application or an AppleScript.
This example shows that you must include the exact path to the index file (you can copy it from the Indexer and paste it into your script):
update "server HD:WebSTAR Server Suite:search:index.search"
end tell
The Dictionaries installed in the WebSTAR Search Data folder, Stopword Dictionary and Substitution Dictionary provide lists used by the search engine in comparing queries with documents.
The Stopword Dictionary is just a list of words (one per line) that are never indexed or searched. These include single letters, HTML tags, and extremely common words such as "allow", "is", and "somewhere". You can change this list and re-create your index to improve responsiveness and reduce inappropriate results.
The Substitution Dictionary helps the search engine match words and their various formats. For example, the past tense of "go" is "went", but this would never be found in a direct comparison. This dictionary allows the index and search tools to make that kind of match.
The format of this dictionary is a list of words, one per line, where a substitution consists of a bullet, followed by a root word, followed by any number of words that should be reduced to that root.
You can edit these files to change or remove entries, add more entries, and include text for languages other than English. Be sure to synchronize the index and the searching by re-creating your indexes if you change the dictionaries.
You can call WebSTAR Search in a number of ways: using HTML forms, search URL links, and WebSTAR SSI <Search> Tags.
To search an index, you must have an interface. The simplest interface is an HTML form. The easiest way to start making such a form is to copy the simple search form file from the Tools & Examples : Search Examples folder. For testing, just change the form action so that it refers to your index, for example:
ACTION="/widgets/widgets.search"
Once you have a form, you can open that page on your server and search your index.
The results of the search will be returned in the pre-defined page format. As you can see with the advanced.html form, WebSTAR Search will display 10 results per page, with page forward and back links, by default.
If a visitor sees the message "The search parameters were not received, probably because you pressed Return instead of clicking on the submit button. Go back, and try clicking the button.", it may also mean that there is no such index. To allow visitors to press the "Return" key in your form, move the "Submit" button out of the table. That way, all the browsers will do the right thing.
You can set up URLs and links in pages that passes the query parameters in the search arguments section of the URL. For example, this URL:
http://www.domain.com/Tools%20%26%20Examples/Search%20Example/Test%20Collection/index.search?query=webstar
will search the example index for the word "webstar", assuming you have created the index and you changed the host name from " www.domain.com " to your host name.
Likewise, the following link, in a file in the Search Examples folder, will search the Test Collections index for the query "web sever":
<A HREF="http://Test%20Collection/index.search?query=web&20server>
Note that the space between "web" and "servers" is encoded ( %20 ). You will have to make sure that all characters are encoded as part of the URL.
Each link can also include parameters, as described Search Parameters .
WebSTAR Search works with WebSTAR SSI to give you more control over the search parameters and the location of the search result. You can set the query in an SSI variable and send that to WebSTAR Search, rather than having the user enter it.
To be sure that your file will be processed by WebSTAR SSI, save it with the .ssi suffix.
You customize the search results page returned to the browser by creating your own SSI page that defines the desired format. Within this SSI page, a <SEARCH...> tag should be inserted at the point where the search results should be inserted. Note that the results are still formatted in the pre-defined layout.
For an example, see the custom.html and custom.ssi files in the Search Examples folder.
The user may specify the several search parameters to the WebSTAR Search Plug-In. These parameters may be specified either via <INPUT> statements in an HTML form, as search arguments to a URL, or as tag parameters to the <SEARCH> tag handler.
WebSTAR Search can automatically update the primary index and any merged indexes at specified intervals. This will take place in the background and should cause no problems to the server, unless you add many large files to a search folder hierarchy all at once. In that case, you should update using the Search Indexer application.
See also Updating Search Indexes .
To enable automatic updating, follow these steps:
http://www.domain.com/pi_admin.search
WebSTAR Search will update the index based on the file modification date. For example, if the index file was modified at 11 AM on a Monday, and you set it update it every 7 days, it will always be updated at 11 am every Monday.