| RDB PRIME! Engineering |
|
|
|
|
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| It is 03:04 PST on Friday 07/31/2026 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
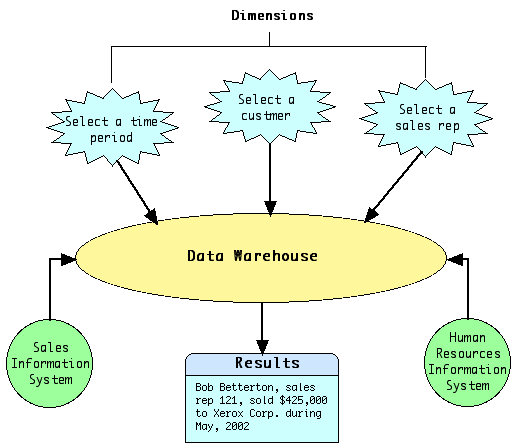
What is a data warehouse? Simply put, a data warehouse could be thought of as a place for secondhand data that originates in either other corporate applications, such as the one our company uses to solve printer problems that are reported from customers, and our front and second line support staff, or some other data source external to our company, such as a public database that contains customer support information gathered from our competitors. Technically, a data warehouse is the coordinated, architected, and periodic copying of data from various sources, both inside and outside the enterprise, into an environment optimized for analytical and informational processing. The key here is that the data is copied (duplicated) in a controlled manner and is copied periodically (batch-oriented processing). Data warehousing is also, therefore, the process of creating an architected information-management solution to enable analytical and informational processing despite platform, application, organizational, and other barriers. The key concept here is that barriers are being broken and distributed information is being consolidated for analysis, although no preconceived notion exists for the exact means of doing so, such as duplicating data. I know that large companies (Xerox being one of them) use software packages that gather and store data in special configurations called data warehouses. Since a data warehouse is an integrated collection of data it can support management analysis and decision making. For example, in a typical company, data is generated by transaction-based systems, such as order entry, inventory, accounts receivable, and payroll. If a user wants to know the customer number on sales order 4077, they can retrieve the data easily from the order entry system application. On the other hand, suppose that a user wants to see May sales results for the sales Rep assigned to a specific customer, as shown in the diagram below for a typical data warehouse.
Although the information systems are interactive, it is difficult for a user to extract specific data that spans several systems and time frames; the average user might need assistance from the IT staff. What's nice about a data warehouse is that rather then accessing separate systems, the data warehouse stores transaction data in a format that allows users to access, combine, and analyze the data. Again, this should help in taming and controlling data volume. A data warehouse allows users to specify certain dimensions, or characteristics. In a consumer products data warehouse, dimensions might include time (temporal), customer, and sales representative. By selecting values for each characteristic, a user can obtain multidimensional information from the stored data. Data warehousing is also a collection of decision support technologies (explained below), aimed at enabling the knowledge worker, who could be an executive, manager, or analyst to make better and faster decisions. The Bill Inmon Data Warehouse: Bill Inmon, the acknowledged father of the data warehouse, defines it as an integrated, subject oriented, time-variant, non-volatile database that provides support for decision making. To understand that definition, lets look at the details:
Data Warehousing: An Example of Replication Complex decision support queries that look at data from multiple sites are becoming very important. The paradigm of executing queries that span multiple sites is simply inadequate for performance reasons. One way to provide such complex query support over DATA from multiple sources is to create a copy of all the data at some one location and to use the copy rather than going to the individual sources. Such a copied collection of data is called a data warehouse. Specialized systems for building, maintaining, and querying data warehouses have become important tools in the marketplace. Data warehouses can be seen as one instance of asynchronous replication, in which copies are updated relatively infrequently, i.e. non-transactional. When we talk of replication, we typically mean copies maintained under the control of a single DBMS, whereas with data warehousing, the original data may be on different software platforms (including database systems and OS file systems) and even belong to different organizations. This distinction, however, is likely to become blurred as vendors adopt more 'open' strategies to replication. For example, some products already support the maintenance of replicas of relations stored in one vendor's DBMS in another vendor's DBMS. However, data warehousing does involve more then just replication. How does it differ from a database? The big difference is that a typical database focuses on one application (i.e., usually transactional-processing based) for analysis of data within a single application domain, i.e. separate systems. For example separate systems could be an order entry application, an inventory application, accounts receivable, and payroll database applications, etc. These systems focus on a particular domain, and are only concerned about that domain. On the other hand with data warehousing, you are concerned about multiable domains (dimensions) to ascertain the relationships and generally get a clear picture of whats going on in the enterprise as a whole. Also, unlike most transactional databases, a data warehouse typically support time-series and trend analysis. Data warehouses are nonvolatile, which means that information in the data warehouse changes far less often and may be regarded as non-real-time with periodic updating. You can also ask the same question above as "How does operational data compare with decision support data". Operational data and DSS data serve different purposes. Therefore, their formats and structures differ. Most operational data are stored in a relational database in which the structures (TABLES) tend to be highly normalized. Operational data storage is optimized to support transactions that represent daily operations. For example, each time an item is sold, it must be accounted for. Customer data, inventory data, parts used data, etc., are in a frequent update mode. In order to provide effective update performance, operational systems store data in many tables, i.e. normalized, each with a minimum number of fields. Thus, a simple sales transaction might be represented by five or more different tables (invoice, invoice line, discount, store, department, etc.) Although such an arrangement is excellent in an operational database, it is not query-friendly. For example, to extract a simple invoice you would have to join several tables. Whereas operational data capture daily business transactions, DSS data give tactical and strategic business meaning to the operation data. From the data analyst's point of view, DSS data differ from operational data in three main areas: timespan, granularity, and dimensionality.
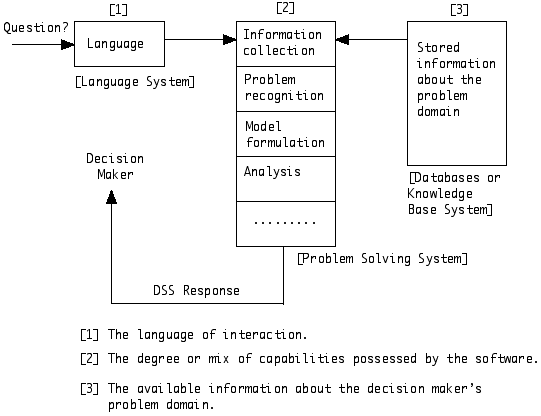
OLAP (Multidimensional OLAP): OLAP (Online Analytical Processing) is "Tell me what happened and why" processing that is done after building the data warehouse. Unlike querying and reporting tools, OLAP functionality enables you to dig deeper, poke around at the data, and come up with the "WHY" aspect of what is happening with the business data. The distinguishing characteristic about OLAP is that it enables you to perform multidimensional analysis. This has historically come about because business users have a natural tendency to view business results in different ways, organized by various dimensions. By using the dimension of time, for example, the user can perform trend analysis. By using other dimensions particular to a business domain (products, business units, and/or geography) the user can get down to the nitty-gritty, nuts-and-bolts of finding problem areas, pinpointing the enterprises strengths, and generally getting a clear picture of what's going on and why it's happening. DSS (Decision Support Systems): A decision support system is a software system that helps management make decisions based on what a manager(s) enters into the system as variables. These input variables help the manager discover new knowledge from the information that is returned. But here is a formal definition: A computer information system that provides information in a given domain of application by means of analytical decision models and access to databases, in order to support a decision maker in making decisions effectively in complex and ill-structured (non-programmable) tasks (Klein and Methlie 1992). DSSs are useful when a fixed goal exists but there is no algorithmic solution. The solutions paths can be numerous and user-dependant (Klein and Tixier, 1971). The bottom line, the goal of a DSS is to improve a decision by better understanding and preparation of the tasks leading towards evaluation and choosing, which is collectively called the decision making process. Below are the software requirements for a DSS:
Below is a conceptual structure of a Decision Support System (Reproduced from Bonczek et al. (1981). Foundations of Decision Support Systems. Academic Press).
What is ment by Additive (facts): Measurements in a fact table that can be added across all the dimensions. Aggregates: Physical rows in a database, almost always created by summing other records in the database for the purpose of improving query performance. Analytic processing: Using data for analytic purposes to support business decision making, versus operational processing, where data is used to run the business. Analytic processing often involves trend analysis, period-to-period comparisons, and drilling. Atomic data: The most detailed granular data captured. Attribute: A column (field) in a dimension table. Composite key: Key in a database made up of several columns, a concatenated key. The overall key in a typical fact table is a subset of the foreign keys in the fact table. In other words, it usually does not require every foreign key to guarantee uniqueness of a fact table row. Conformed dimensions: Dimensions are conformed when they are either exactly the same (including the keys) or one is a perfect subset of the other. More important, the row headers produced an answer sets from two different conformed dimensions must be able to be matched perfectly. Cube: Name for a dimensional structure on a multidimensional or OLAP database platform, originally referring to the simple three-dimension case of product, market, and time. Data mart: A logical and physical subset of the data warehouse's presentation area. Originally, data marts were defined as highly aggregated subsets of data, often chosen to answer a specific business question. This definition was unworkable because it led to stovepipe data marts that were inflexible and could not be combined with each other. This first definition has been replaced, and the data mart is now defined as a flexible set of data, ideally based on the most atomic (granular) data possible to extract from an operational source, and presented in a dimensional model that is more resilient when faced with unexpected user queries. Data marts can be tied together using drill=across techniques when their dimensions are conformed. We say these data marts are connected to the data warehouse bus. In its most simplistic form, a data mart represents data from a single business process. Ê Denormalize: Allowing redundancy in a table so that the table can remain flat in order to optimize performance and ease of use (Second normal form). Dimension: An independent entity in a dimensional model that serves as an entry point or as a mechanism for slicing and dicing the additive measures located in the fact table of a dimensional model. Dimension Table: A table in a dimensional model with a single-part primary key and descriptive attribute columns. Dimensional modeling: A methodology for logically modeling data for query performance and ease of use that starts from a set of base measurement events. In the RDBMS environment, a fact table is constructed generally with one record for each discrete measurement. This fact table is then surrounded by a set of dimension tables describing precisely what is known in the context of each measurement record. Because of the characteristic structure of a dimensional model, it is often called a star schema. Drill across: The act of requesting similarly labeled data from two or more fact tables in a single report, almost always involving separate queries that are merged together in a second pass by matching row headers. Drill down: The act of adding a row header or replacing a row header in a report to break down the rows of the answer set more finely. Drill up: The act of removing a row header or replacing a row header in a report to summarize the rows of the answer set. Dynamic aggregation. Fact: A business performance measurement, typically numeric and additive, that is stored in a fact table. Fact table: In a dimensional model, the central table with numeric performance measurements characterized by a composite key, each of whos elements is a foreign key drawn from a dimension table(s). Grain: The meaning of a single row in a fact table. Granularity: The level of detail captured in the data warehouse. Ê Normalize: A logical modeling technique that removes data redundancy by separating the data into many discrete entities, each of which becomes a TABLE in a RDBMS. Redundancy: Storing more than one occurrence of the data. Star-join schema: The generic representation of a dimensional model in a relational database in which a fact table with a composite key is joined to a number of dimension tables, each with a single primary key. Describe the characteristics of a data warehouse. Divide them into functionality of a data warehouse and advantages users derive from it.
What is the multidimensional data model (MDM)? The multidimensional data model is a good fit for OLAP (Online Analytical Processing) and decision support (DSS) technologies as explained above. But basically, multidimensional models (databases) throw out the conventions of their relational ancestors and organize data in a manner that's highly conductive to multidimensional analysis. Multidimensional analysis is built around a few simple data organization concepts, specifically "facts" and "dimensions". FactsA fact is an instance of some particular occurrence or event and the properties of the event all stored in a database. For example, did you sell a computer to a customer last Thursday evening? That's a fact. Did the warehouse receive a shipment of 45 power supplies yesterday from a particular suppler? That's another fact. DimensionsA dimension is an index by which you can access facts according to th value (or values) you want. For example, you may organize your shipping data according to this dimensions:
This is known as a three dimensional matrix, which could be represented using a data cube. Theoretically, you can have as many dimensions in your multidimensional model as necessary. This is known as a data hypercube, however, visualization is not easily accomplished. With a data hypercube design, one has to ask the question, will your multidimensional database product support this structure? A more important question, though, is that even if a product allows 15 dimensions for a hypercube, does it make sense to create a model of this size? Areas that need consideration are efficiency and storage-management for this model. How is it used in data warehousing? As a basic example, you can organize and view your sales data as a three-dimensional array (cube), indexed by the following dimensions given above:
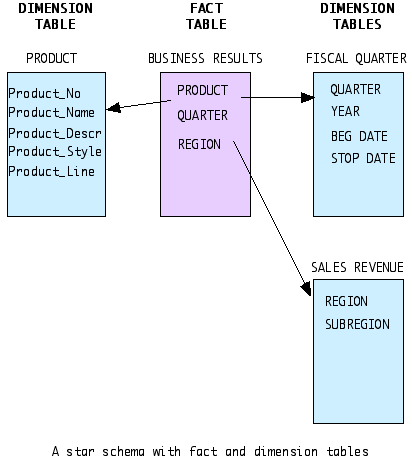
In the above example note the subtle difference between the way the dimensions are used. In the first, time relates to a month; customer relates to a specificÊcustomer; and product is for a specific product. In the second example, however, time is for a year, not a month; customer is still the same (an individual customer); and product is for the entire product line. Multidimensional analysis supports the notion of hierarchies in dimensions. That is, time may be organized in a hierarchy of year -> quarter -> month. You could view facts (or consolidation of facts) in the database as any one of these levels: year, quarter, or month. Similarly, products may be organized in a hierarchy of product family --> product type --> specific products. Class rings may be a product type; "class ring, modern style, onyx stone" may be a specific product. Furthermore, class rings, watches, other rings, and other items all would "roll-up" into the jewelry product family. Levels of hierarchy enable the ability for "drill-down". Drill-down is associated with OLAP, and is a feature that is frequently used by users. The concept is fairly simple: As required, one sees selective increasing levels of detail in the data that is presented. Define theses terms: Star Schema,A star schema is one of the common multidimensional schemas. The Star Schema consists of a fact table with a single table for each dimension as shown in the diagram below (Elmasri and Navathe, 2000). This method mimics the multidimensional structures of facts and dimensions, and uses relational fact tables and dimension tables. The star schema is recommended for relational databases used for OLAP (online analytical processing), also known as ROLAP.
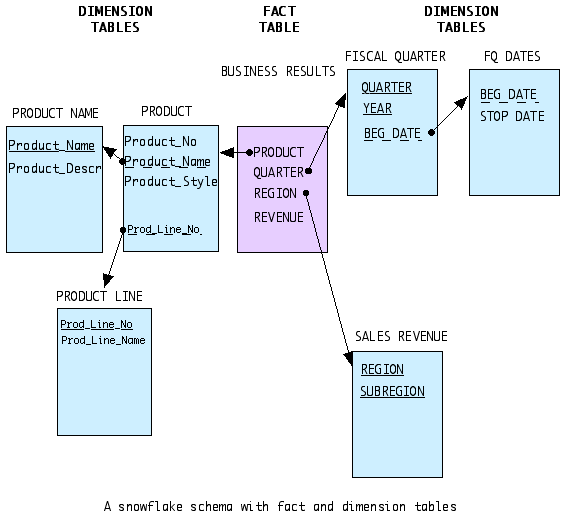
Snowflake Schema,The snowflake schema is a variation on the star schema in which the dimensional tables from a star schema are organized into a hierarchy by normalizing them. See the diagram below (Elmasri and Navathe, 2000).
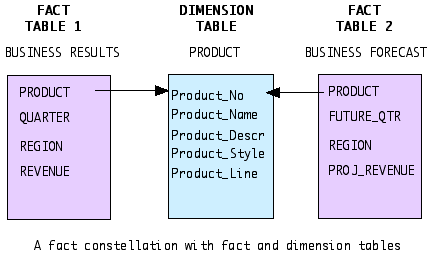
Fact Constellation,A fact constellation is a set of fact tables that share some dimension tables, see figure below (Elmasri and Navathe, 2000).
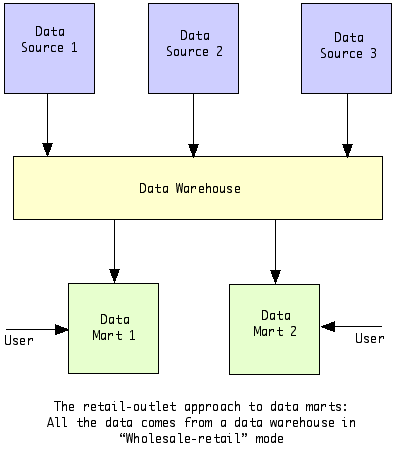
This figure, shows a fact constellation with two fact tables, business results and business forecast. These share the dimension table called product. Fact constellations limit the possible queries for the data warehouse. Data Marts.Simply stated, a data mart is a scaled-down (subset) data warehouse, thats it. Elmasri and Navathe (2000) also state it this way: Data marts generally are targeted to a subset of the organization, such as a department, and are more tightly focused. Many data warehousing experts would argue that a true data mart is a "retail outlet" with its contents provided from a data warehouse, see the diagram below.
This Page has been accessed " 12878" times. | |||||||||||||||||||||||||||||||||||||||||||||||||||